DCS292 - Compiler Construction Laboratory 2022 Spring
设计词法分析器
编译器的前端一般接受源程序代码,通过进行词法分析(Lexical Analysis)得到词法单元(token)序列,再进行语法分析得到语法分析树,再进行语义分析得到语义树。本次实验设计的词法分析器主要组成部分是扫描器,它通过对目标源码的扫描和参考 token 类别码表生成 token 类别码序列,包括每一个单词及其种类枚举值,每行一个单词。
设计类别码
C 语言的源代码中一般含有以下组成部分,我们为它们标上序号便于识别。此处支持的关键字是 C89 的 32 个关键字, C99 和 C11 分别增加了 5 个和 7 个关键字,这里暂不考虑。
0
1
2
3
4
5
标识符 00 reserveWords, _count, RGB2HSV, is_digit, ...
字符 01 'c', 'd', ...
字符串 02 "Hello world!", "zzzZ", ...
常数 03 0, 1.1, -2.7e-22, .05f, 27ull, ...
关键字 04 - 35 auto, for, break, if, else, sizeof, ...
界符 36 - 71 +, -, (, >>, &&, ~, \, ...
设计自动机
首先来看一个简单的 C 程序源码
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#include <stdio.h>
// ----------------------------------------------------------------
// Function: main
// Purpose: main function
// Parameters:
// int argc - number of arguments
// char *argv[] - array of arguments
// Returns:
// int - 0 if successful, 1 if error
// ----------------------------------------------------------------
int main(int argc, char *argv[]) {
/*
Test multiline comment
int a = 0;
int b = 0;
int c = a + b;
printf("Hello, World!\n");
*/
printf("Hello, World!\n");
static const unsigned int a = 0;
float b = .01;
double c = -3.14159;
double d = -1.414e-2;
char AbCd_e = 'a';
if(b*c <= d || b*c >= a) printf("b*c is less than or equal to d or greater than a\n");
else printf("b*c is greater than d and less than a\n");
return 0;
}
第一行第一个字符是 #,这是一个宏。由于这是预处理器所做的事情,所以我们打算把所有宏都过滤掉。因此这一行在经过一个叫过滤器的东西的时候只会留下一个换行符。一开始我的过滤器没有留下换行符,导致经过过滤器的代码变成了一行长长的字符串,这不但难看,还不利于报错时的定位。所以应该在过滤阶段保留换行符。
第二行到第十行是一个函数功能的介绍的注释,是九个单行注释,以 // 开头。过滤器也应该在预处理阶段过滤掉注释。第十二行到第十八行则是一个多行注释,它以 /* 开头,以 */ 结尾,我们的过滤器应该过滤掉区间内的所有文字,只保留换行符。
第十一行是主函数的声明。首先是 int ,这是一个保留字,说明函数的返回值是整形。它以字母打头。我们知道所有的保留字都以字母或者下划线 _ (C89 之后)开头。所以当遇到字母或者下划线 _ 开头的,并且后续都是字母,下划线或数字的,除了是保留字外,就是标识符。
在 main 之后,我们遇到一个 (,这是一个界符。
在第十九行,我们在 printf() 里面出现了一个字符串。字符串是双引号开始和结束的。
在第二十行,我们把常数整形 0 赋值给变量 a。接下来的数字,基本以 0,.开头。当然我发现其实还有更复杂的开头,其中的判定也比较复杂,在下面会展开来讲。
第二十四行出现了单引号开始和结束的单个字符。但是也有可能是这样的情况 '\t' 所以要判断是否出现转义符。其实 'aa' 这种多字符的字符类型在我的 gcc 中只会显示 warning,这在之后的实现也会展开来讲。
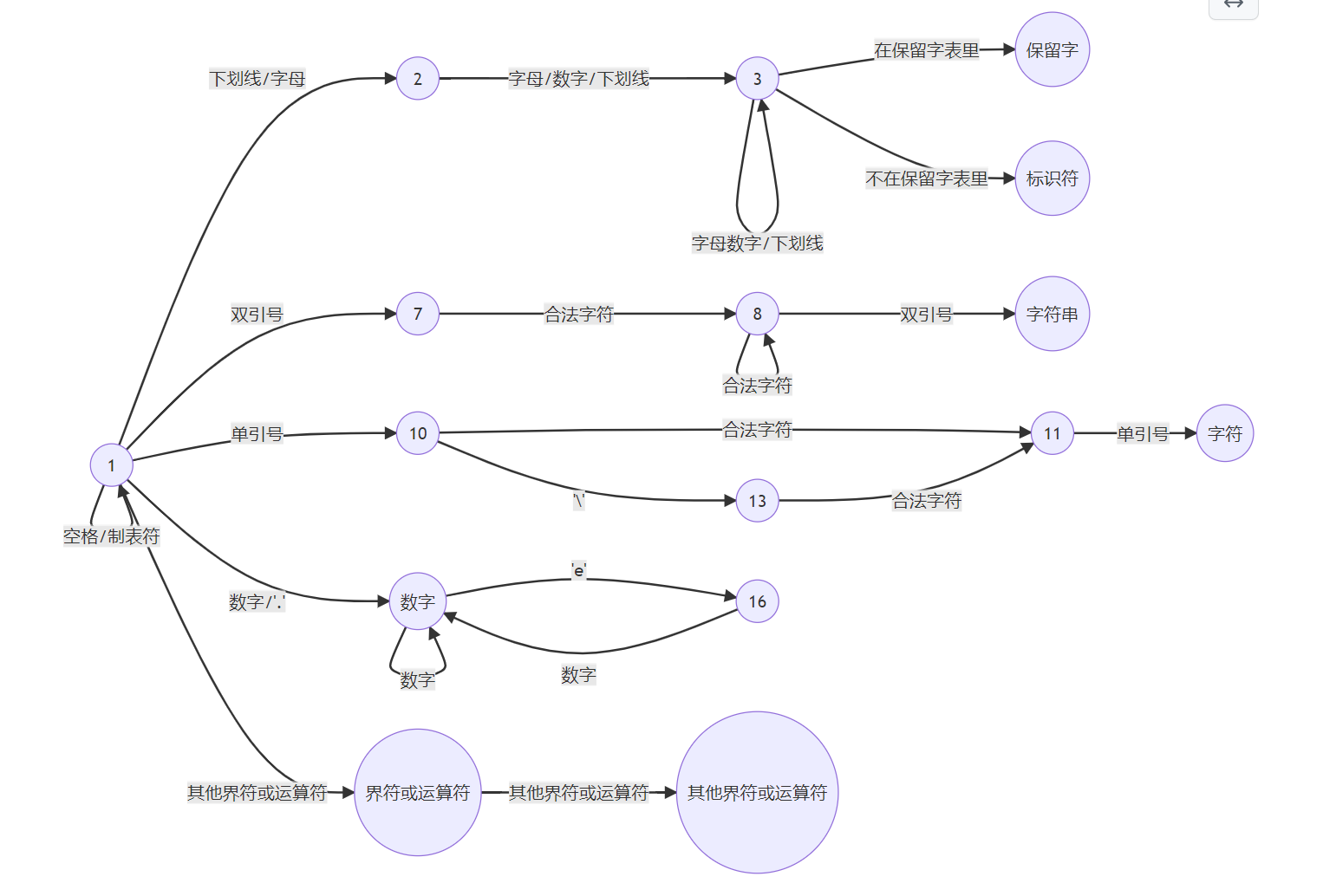
现在我们大概掌握了一些自动机的规则,总结如下:
- 以下划线/字母开头的含字母/下划线/数字的是保留字或标识符
- 双引号开头双引号结尾的是字符串
- 单引号开头单引号结尾的是字符
- 数字或小数点后面是数字开头的是数字
- 界符或运算符开头的是界符或运算符
接下来研究一下 C 中的数字的表示方法。以下列出了常见的数字表示方法。比如我们在整数后可以加上 ull/llu/l/u/ll/ul/lu 的的后缀,其中 l/ll 是 long/long long 的意思,而 u 是 unsigned 的意思。不同后缀可以大小写混用也可以随意排列,如 Ull/LLu 都是合法的,但是 Ll 是不合法的。再比如,C 默认浮点数常量是 double ,要令他们为 float ,可以后缀 f,要令他们为 long double 或者 long long double 则可以加 l/ll ,但是不可以加 u。科学计数法的 e 后只能是整数,不能出现小数点。C89 可以在整数前加上 0x/0X 表示使用16进制,加上 0 表示8进制,加上 0b/0B 表示二进制。C99 支持使用浮点数的指数形式来表示不同进制,使用 p/P 代替 e/E 。在这里我们使用 C89 标准,不予考虑。
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int 0abc; // error invalid suffix "abc" on constant 0
long long a = 0llu; // pass
float b = .01f; // pass
double c = -3.14159l; // pass
float d = -1.414E-2f; // pass
char AbCd_e = 'a'; // pass
double f = 1e-2.123; // error invalid suffix ".123" on constant 1e-2
double g = 1e-1; // pass
double h = 1.1e+1 - 1; // pass
char i = 'gg'; // warning
char j = '\n'; // pass
int k = 0x11; // pass
int l = 011; // pass
int m = 0b11; // pass
int n = 0b1110_0011; // error invalid suffix "_0011" on constant 0b1110
long long o = 11LLU; // pass
long double p = 1e1l; // pass
long double q = 1e1u; // error invalid suffix "u" on constant 1e1
long double r = 1e1e1; // error invalid suffix "e1" on constant 1e1
现在我们将数字的自动机单独列出
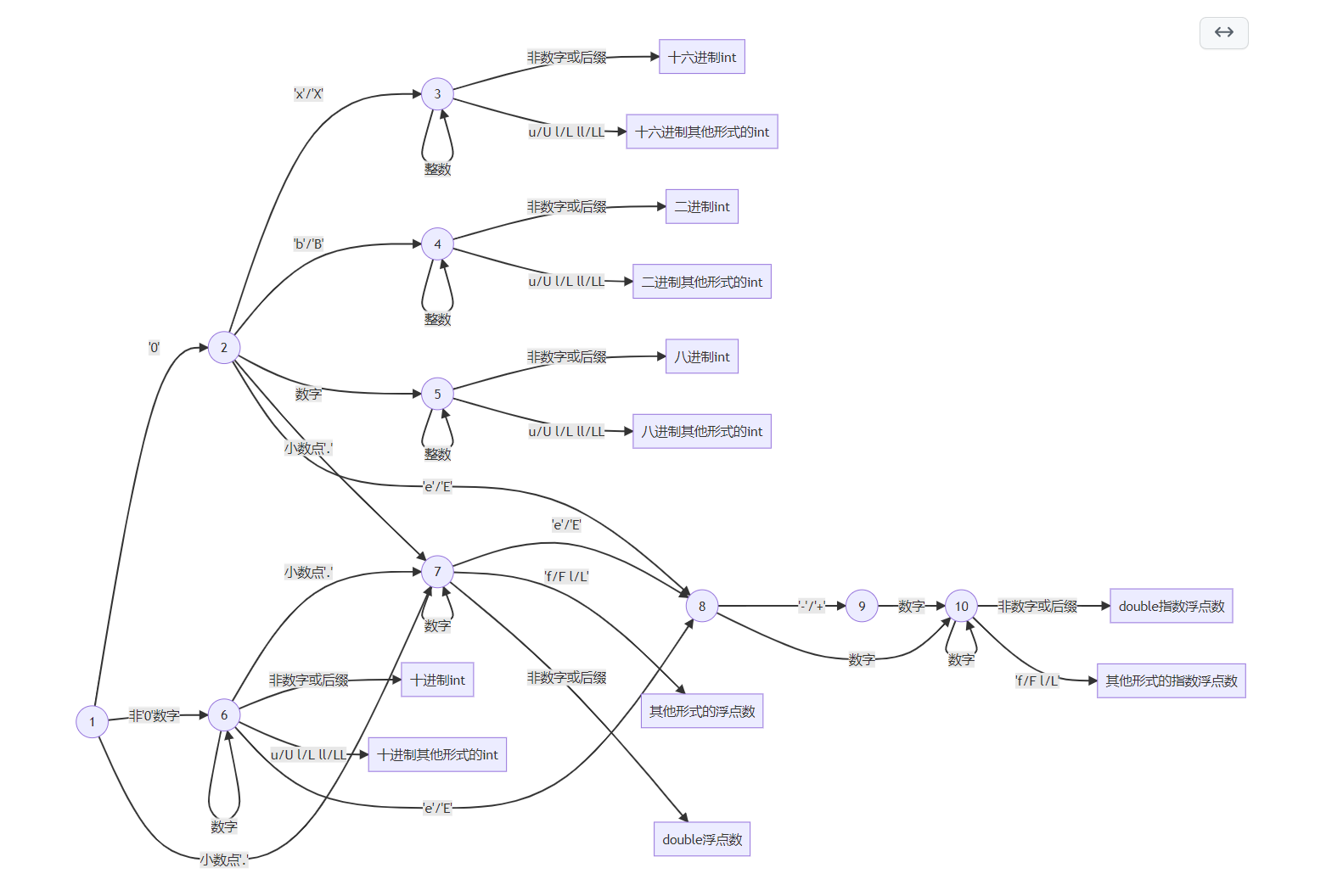
看起来有点复杂,我们可以结合上面列出的示例,比如指数部分必须是整数,只有 long double 没有 long long double,也没有 unsigned double 等等等等。在代码实现中我们使用了函数来调用处理后缀的方式使得看起来相较于自动机来说更加直观。
使用 C++ 代码实现
定义类别码
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#define IDENTIFIER 00
#define CHARACTER 01
#define STRING 02
#define NUMBER 03
#define ENDOFCODE 99
// reserve words table C89 04 - 35 (32)
static char ReserveWords[32][12] = {
"auto", "break", "case", "char", "const", "continue",
"default", "do", "double", "else", "enum", "extern",
"float", "for", "goto", "if", "int", "long",
"register", "return", "short", "signed", "sizeof", "static",
"struct", "switch", "typedef", "union", "unsigned", "void",
"volatile", "while"};
// operator or delimiter table C89 36 - 71 (36)
static char OperatorOrDelimiter[36][3] = {
"+", "-", "*", "/", "<", ">", "=", "!", ";",
"(", ")", "^", ",", "\"", "\'", "#", "&", "|",
"%", "~", "[", "]", "{", "}", "\\", ".", "\?", ":",
"&&", "||", "<<", ">>", "==", "<=", "!=", ">="};
根据我们设计的类别码,定义上面的宏和数组。
注意当检查到储存源代码的字符串中出现 \0 时说明程序结束,返回类别码 99。
定义常用功能函数
接下来定义一些我们常用的功能函数,为了提升性能,大部分简短的函数使用了 inline 的声明。
0
1
2
3
4
5
inline bool isDigit(const char c);
inline bool isLetter(const char c);
inline int isReservedWord(const char *str);
inline bool isFirstOfOperatorOrDelimiter(const char c);
inline bool isSecondOfOperator(const char c);
inline int isOperatorOrDelimiter(const char *str);
注意到两个返回 int 的函数,如果出现在保留字表或者界符运算符表中,它们会返回这个字符串的类别码。否则返回的是 -1。
另外有两个分别判断字符是否为界符或者运算符的第一位和判断字符是否为运算符第二位的函数。为了加速判断第二位的速度,我将两字符的运算符集中在表中末尾,这样或许可以提高一些速度。比较合理的想法是分析许多代码,找到使用频率最高的符号放在表中靠前,这样也能提升运行速度,但是懒惰的我并没有这么做,尽管编译器的性能极大取决于这种函数的细节,但是我的这个作业显然并没有编译 demo.c 以外的代码的宏图大志。
0
1
2
3
4
5
6
7
inline bool isSecondOfOperator(const char c) {
if (c == '\0') return false;
for (int i = 28; i <= 35; i++)
// there is no 2-character operator before 28
if (c == OperatorOrDelimiter[i][1])
return true;
return false;
}
实现宏和注释的过滤
0
bool filter(char *str, const int len);
这将是读入文件后调用的相当于一个预处理器的函数。它的实现大概在第 500 行左右,功能包括
- 检测到
#且前一个符号是换行符号或此行是第一行时不读入这一行的内容直到换行符 - 检测到
//不读入后面的内容直到换行符 - 检测到
/*不读入后面的内容除了换行符,直到*/出现
词法分析扫描器类
我一开始尝试使用实验资料里面的循环自动机的框架来写程序,但是写出来十分的丑,且可读性很差。于是我将状态转移改成函数调用,看起来可能复杂一些,但是我认为可读性和可维护性增加了。
最后我把这些函数集合到一个类中,定义如下:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class Scanner {
public:
Scanner() : str(nullptr), p(0), row(1), col(1){};
Scanner(char *str) : str(str), p(0), row(1), col(1){};
~Scanner(){};
bool scan(char *token, int &syn);
inline char *getString(void) const { return str; };
inline void setString(char *str) { this->str = str; };
inline int getPos(void) const { return p; };
inline void setPos(int p) { this->p = p; };
inline int getRow(void) const { return row; };
inline void setRow(int row) { this->row = row; };
inline int getCol(void) const { return col; };
inline void setCol(int col) { this->col = col; };
private:
inline void handleTypeSuffix(char *token, unsigned int &token_index, const bool is_double);
inline void handleInvalidSuffix(char *token);
inline bool binaryNumber(char *token, int &syn, unsigned int &token_index);
inline bool octalNumber(char *token, int &syn, unsigned int &token_index);
inline bool decimalNumber(char *token, int &syn, unsigned int &token_index);
inline bool hexadecimalNumber(char *token, int &syn, unsigned int &token_index);
inline bool tokenStartWithDigitOrDot(char *token, int &syn, unsigned int &token_index);
inline bool tokenStartWithOperatorOrDelimiter(char *token, int &syn, unsigned int &token_index);
inline bool tokenStartWithSingleQuote(char *token, int &syn, unsigned int &token_index);
inline bool tokenStartWithDoubleQuote(char *token, int &syn, unsigned int &token_index);
inline bool tokenStartWithLetter(char *token, int &syn, unsigned int &token_index);
inline void rightShift(char *token, unsigned int &token_index, unsigned int num);
char *str;
int p, row, col;
};
私有变量
私有变量 str 指向源代码字符串数组,p 是本扫描器在此字符串上的游标,指向当前处理的位置,row 是此游标在源代码文件中的行数,col 是此游标在源代码文件中的列数。
rightShift()
为了方便在扫描时同时增加 p 和记录行数列数,私有函数 rightShift 提供向右扫描并记录进 token 数组的功能。它默认扫描一位,也可以扫描多位,实现如下:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
inline void Scanner::rightShift(char *token, unsigned int &token_index, unsigned int num = 1) {
if (token_index + num > TOKEN_LEN) {
std::cerr << "\033[31mError:\033[0m token length overflow" << std::endl;
#if STOPWHENERROR
// exit(1);
#endif
p += num;
return;
}
while (num--) {
if (str[p] == '\n') {
row++;
col = 1;
} else {
col++;
}
token[token_index++] = str[p++];
}
}
Scan()
在对这个扫描器初始化之后,就可以开始扫描了。首先,当私有变量 str 没有指向代码时扫描不了,返回 false 。然后开始,遇到空格和换行右移,其他制表符在上一步已经被过滤掉了。然后将 token 清零,开始判断,根据 token 的第一个字符进入不同的状态,也就是调用不同的函数。
tokenStartWithLetter()
0
1
2
3
if (isLetter(str[p]) || str[p] == '_') {
// start with a letter must be a reserved word or an identifier
return tokenStartWithLetter(token, syn, token_index);
...
这一部分判断标识符和保留字
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
inline bool Scanner::tokenStartWithLetter(char *token, int &syn, unsigned int &token_index) {
/*
generate a token start with a letter
@return: always return true
*/
rightShift(token, token_index);
while (isLetter(str[p]) || isDigit(str[p]) || str[p] == '_') {
rightShift(token, token_index);
}
token[token_index] = '\0';
syn = isReservedWord(token);
if (syn == -1) {
syn = IDENTIFIER; // if not a reserved word, it is an identifier
}
return true;
}
这部分的逻辑和自动机都比较简单。遇到字母/下划线/数字就继续读,然后整个串去保留字表里面查找,找到了就是保留字,找不到就是标识符。这里保留字表也应该找到使用频率最高的关键词放在表中靠前,这样能提升运行速度。以后有时间研究研究别人的编译器是咋写的。
tokenStartWithDigitOrDot()
0
1
2
3
else if (isDigit(str[p])) {
// start with a digit must be a number
return tokenStartWithDigitOrDot(token, syn, token_index);
...
这部分判断数字开头的,上面已经基本分析的比较详尽了,比较麻烦,因此写了诸多函数供这个函数调用。
按开头分为十六进制、八进制、二进制、十进制表示法,分别调用 hexadecimalNumber()、octalNumber()、binaryNumber()、decimalNumber() 四个函数。
hexadecimalNumber()
首先进入这个函数,把头两位 0x/0X 读进 token 然后注意十六进制中字符范围,开始读,最后若出现后缀,转到后缀处理函数处理后缀。处理完后缀后面跟的若不是运算符或者界符,则是非法后缀。
0
1
2
3
while (isDigit(str[p]) || (str[p] >= 'a' && str[p] <= 'f') ||
(str[p] >= 'A' && str[p] <= 'F')) {
rightShift(token, token_index);
}
八进制和二进制与此相差不大,此处不再赘述。
decimalNumber()
处理十进制数相对比较麻烦一些,因为 C89 没有其他进制的浮点表示,所以其他进制就相对比较简单。不过有了上面的分析我们也可以有条理地写出来。
首先进入这个函数定义了俩变量,存储是否遇到 . & e/E 还有是否是个非法的数字,也就是带了非法后缀。本来这个非法数字在这个函数内会判断然后报错,但是后来情况太多,写了另一个函数来处理后缀,报错也写进那个函数 handleTypeSuffix() 里面,这个非法数字就不报错,仅仅在非法数字成立的时候这个函数返回 flase。
之后进入主循环,科学计数法只能有一个 e/E 若已经读过了就报错,小数点也同理。同时 e/E 后可以加 +/- ,但是后面只能跟整数。最后根据是否出现小数点和指数符号来判断是整形还是浮点型,进入后缀处理阶段。
handleTypeSuffix()
这里匹配合法后缀。
我们在整数后可以加上
ull/llu/l/u/ll/ul/lu的的后缀,其中l/ll是long/long long的意思,而u是unsigned的意思。不同后缀可以大小写混用也可以随意排列,如Ull/LLu都是合法的,但是Ll是不合法的。再比如,C 默认浮点数常量是double,要令他们为float,可以后缀f,要令他们为long double或者long long double则可以加l/ll,但是不可以加u。科学计数法的e后只能是整数,不能出现小数点。
这个函数写的相当暴力,根据传入参数确定是整形或浮点型,为它们匹配相应的后缀。
handleInvalidSuffix()
这个函数处理非法后缀,并将它们在报错中打印出来。我模仿了 gcc 的报错方式,指出了错误位置和类型,但是没有花时间做到想它一样画下划线。
tokenStartWithSingleQuote()
由于有些字符前面有转义符,且 gcc 默认允许多字符的字符常量,只会警告。因此读完再判断是否是多字符常量。
tokenStartWithDoubleQuote()
由于 C 语言中可以用 \\ 来强制换行,所以研究了下在字符串中使用这个符号,是可以使用的,但是会出现一个警告。
实验验证
demo.c
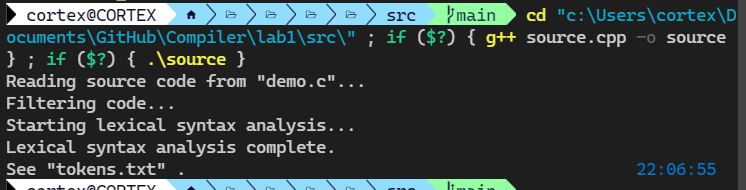
我先把一个正常的上面的示例,也就是 demo.c 进行词法分析。程序未报错,得到 tokens.txt 下面展示一部分。
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
<int, 20>
<main, 0>
<(, 45>
<int, 20>
<argc, 0>
<,, 48>
<char, 7>
<*, 38>
<argv, 0>
<[, 56>
<], 57>
<), 46>
<{, 58>
<printf, 0>
<(, 45>
<"Hello, World!\n", 2>
<), 46>
<;, 44>
<static, 27>
<const, 8>
<unsigned, 32>
<int, 20>
<a, 0>
<=, 42>
<0, 3>
<;, 44>
<float, 16>
<b, 0>
<=, 42>
<0.01, 3>
<;, 44>
可以看到 int 是一个保留字,类别码是 20。main 是个标识符,注意,main 虽然是程序的入口,但是它并不是保留字,所以它的类别码是 0。接下来是左括号,它属于界符,类别码是 45。
第 16 行出现了一个字符串,它的类别码是 2。第 25 行出现了一个整形常量,类别码是 3。第 30 行出现的浮点数常量类别码也是 3。
wrong_demo.c
这个程序是为了测试报错而写的,代码见附录。首先我们把 STOPWHENERROR 宏设置为 true,这会在分析器遇到错误的时候报错并直接退出程序,若设为 false 则强制继续运行。
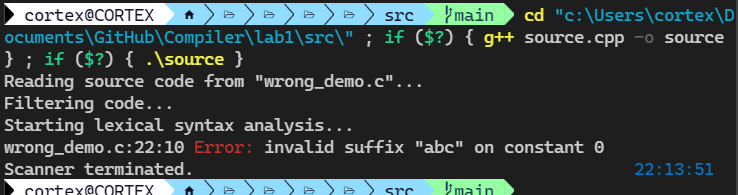
可以看到遇到了错误直接停止运行,错误的这行是
0
int 0abc; // error
把 STOPWHENERROR 宏设置为 false,再次运行。
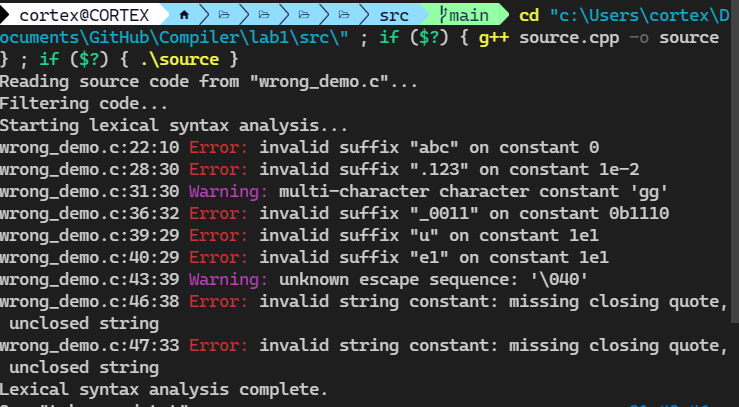
可以看到扫描到了程序最后,把应该有的报错都打印来了。
再尝试使用 gcc 编译这个错误的程序,我们发现报错的项目是一样的。
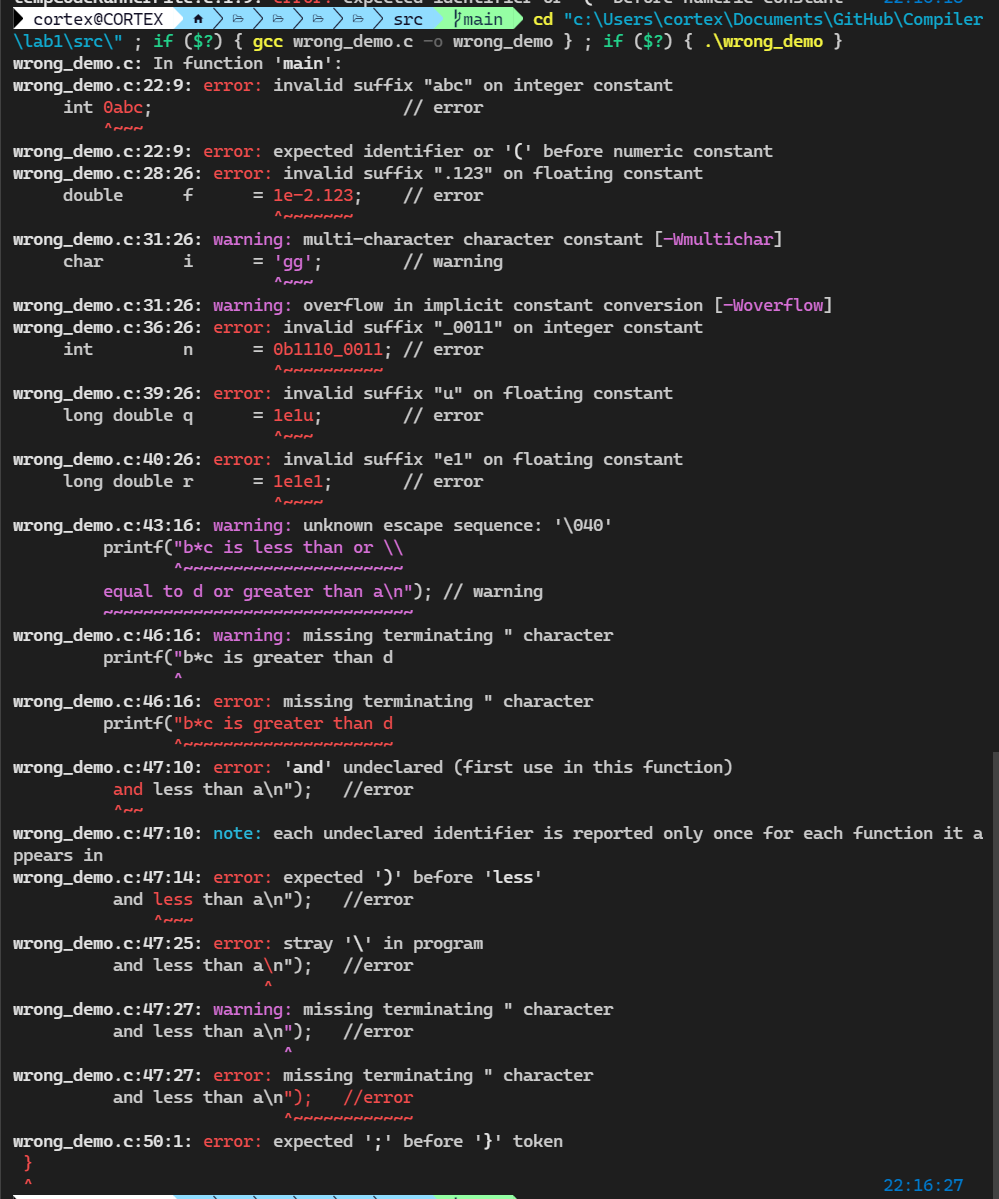
相比 gcc 的报错,这个解析器的报错能力有待提高。当然这些报错都是我根据 gcc 的报错推断出来写的。
总结
这个代码改到现在已经和第一版相差很多了。第一版只有三百行,充满了长长瘦瘦的 switch 和看不懂的自动机代码。之后写了个大大的扫描器函数,又觉得很丑,把代码分成许多函数。最后又写成了一个类。
由于代码功力不足,写的确实看不出有现代 C++ 的特色,更像是 C99 with class 什么鬼的。代码风格也很丑,注释基本是 copilot 给我补的,性能也做不好,只会疯狂 inline ,生怕编译器不知道我这短短几行代码全给我揉成一堆跑也一样快不到哪里去。
比较满意的是基本考虑齐了 C89 的数字表示,做了比较完备的报错。当然这并不是什么高超的技巧和值得称道的东西。
报错这个东西,一开始也不知道怎么搞,想去人家的开源代码了解了解,也看不清楚。总是靠函数返回值靠 if 语句也受不了,同学说用 try-catch,感觉也并不优雅。不过倒是让我明白了一件事,就是我一直遵守谷歌开源提倡的不使用 try-catch,然而现在对这个的看法是 try-catch 性能损耗并不会很大,以后可以放心使用。
比较理想的是整一个类来处理这些报错,用代码来区分错误,也不用在代码里写这么多字符串。
数字后缀的处理暴力写了许多分支,其实并不利于维护,也很丑。但是后缀好像也就那几个排列组合,先将就着用吧。
本次实验倒是让我了解了 C/C++ 的发展历史,因为以前没去注意这些东西,现在看来觉得受益匪浅。
References
Appendix
wrong_demo.c
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#include <stdio.h>
// ----------------------------------------------------------------
// Function: main
// Purpose: main function
// Parameters:
// int argc - number of arguments
// char *argv[] - array of arguments
// Returns:
// int - 0 if successful, 1 if error
// ----------------------------------------------------------------
int main(int argc, char *argv[]) {
/*
Test multiline comment
Error: invalid suffix "abc" on constant 0
Error: invalid suffix ".123" on constant 1e-2
Warning: multi-character character constant 'gg'
Error: invalid suffix "_0011" on constant 0b1110
Error: invalid suffix "u" on constant 1e1
Error: invalid suffix "e1" on constant 1e1
*/
printf("#Hello, World!\n");
int 0abc; // error
long long a = 0llu; // pass
float b = .01f; // pass
long double c = -3.14159l; // pass
float d = -1.414E-2f; // pass
char AbCd_e = 'a'; // pass
double f = 1e-2.123; // error
double g = 1e-1; // pass
double h = 1.1e+1 - 1; // pass
char i = 'gg'; // warning
char j = '\n'; // pass
int k = 0x11; // pass
int l = 011; // pass
int m = 0b11; // pass
int n = 0b1110_0011; // error
long long o = 11LLU; // pass
long double p = 1e1l; // pass
long double q = 1e1u; // error
long double r = 1e1e1; // error
double s = .2e-4l; // pass
if (b * c <= d || b * c >= a)
printf("b*c is less than or \\
equal to d or greater than a\n"); // warning
else
printf("b*c is greater than d
and less than a\n"); //error
return 0;
}
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.