DCS293 - High Performance Computing 2021 Fall
前言
CUDA (Compute Unified Device Architecture,统一计算设备架构) 是一种将 GPU 作为数据并行计算设备的软硬件体系,是显卡厂商 NVIDIA 在 2007 年推出的并行计算平台和编程模型。它利用图形处理器 (GPU) 的能力,实现计算性能的显著提高。它包含了 CUDA 指令集架构 (ISA) 以及 GPU 内部的并行计算引擎。开发人员可以使用 C/C++ 语言来为 CUDA 架构编写程序。CUDA 提供 host-device 的编程模式以及非常多的接口函数和科学计算库,通过同时执行大量的线程而达到并行的目的。
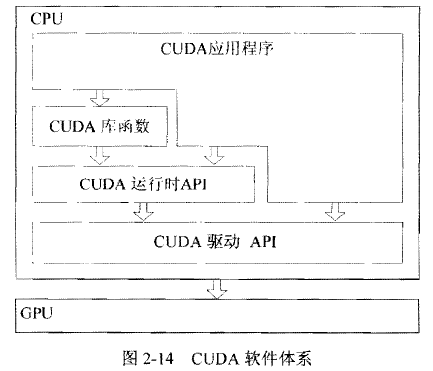
CUDA的软件堆栈由三层构成,如下图,CUDA Library、CUDA runtime API、CUDA driver API. CUDA 的核心是CUDA C 语言,它包含对 C 语言的最小扩展集和一个运行时库,使用这些扩展和运行时库的源文件必须通过 nvcc 编译器进行编译。 CUDA C 语言编译得到的只是 GPU 端代码,而要管理 GPU 资源,在 GPU 上分配显存并启动内核函数,就必须借助 CUDA 运行时 API (runtime API) 或者 CUDA 驱动 API (driver API) 来实现。在一个程序中只能使用 CUDA 运行时 API 与 CUDA 驱动 API 中的一种,不能混合使用。
实验环境
Linux jupyter-zhamao 5.4.0-74-generic #83~18.04.1-Ubuntu SMP
Intel(R) Xeon(R) Gold 6242 CPU @ 2.80GHz 16 cores 32 processors
NVIDIA Tesla V100-SXM2-32GB × 4
- Driver Version: 440.33.01
- CUDA Version: 10.2
CUDA GEMM
使用 CUDA 并行矩阵乘法的思路和使用其他方法的思路差不多,每个线程计算一个块,这里每个块为一个元素。
指定二维 blockSize 大小,根据矩阵规模计算出 gridSize 大小。每个元素都由一个 CUDA Thread 计算。
0
1
2
dim3 blockSize(BLOCK_SIZE, BLOCK_SIZE);
dim3 gridSize((MATRIX_SIZE + blockSize.x - 1) / blockSize.x,
(MATRIX_SIZE + blockSize.y - 1) / blockSize.y);
在主函数申请空间,初始化矩阵 A 和 B。
0
1
2
3
4
5
6
7
8
9
10
float *A = (float *)malloc(sizeof(float) * MATRIX_SIZE * MATRIX_SIZE);
float *B = (float *)malloc(sizeof(float) * MATRIX_SIZE * MATRIX_SIZE);
float *C = (float *)malloc(sizeof(float) * MATRIX_SIZE * MATRIX_SIZE);
srand(0);
for (int i = 0; i < MATRIX_SIZE; i++) {
for (int j = 0; j < MATRIX_SIZE; j++) {
A[i * MATRIX_SIZE + j] = (float)rand() / RAND_MAX;
B[i * MATRIX_SIZE + j] = (float)rand() / RAND_MAX;
}
}
然后开始计时,再在设备上申请空间,并把矩阵 A 和 B 复制到设备上。
0
1
2
3
4
5
6
7
clock_t startTime = clock();
float *cuda_A, *cuda_B, *cuda_C;
cudaMalloc((void **)&cuda_A, sizeof(float) * MATRIX_SIZE * MATRIX_SIZE);
cudaMalloc((void **)&cuda_B, sizeof(float) * MATRIX_SIZE * MATRIX_SIZE);
cudaMalloc((void **)&cuda_C, sizeof(float) * MATRIX_SIZE * MATRIX_SIZE);
cudaMemcpy(cuda_A, A, sizeof(float) * MATRIX_SIZE * MATRIX_SIZE, cudaMemcpyHostToDevice);
cudaMemcpy(cuda_B, B, sizeof(float) * MATRIX_SIZE * MATRIX_SIZE, cudaMemcpyHostToDevice);
调用核函数进行计算。
0
GEMM_CUDA<<<gridSize, blockSize, 0>>>(cuda_A, cuda_B, cuda_C, MATRIX_SIZE);
核函数如下。
0
1
2
3
4
5
6
7
8
9
__global__ void GEMM_CUDA(const float *A, const float *B, float *C, const int mat_size) {
const int row = threadIdx.y + blockIdx.y * blockDim.y;
const int col = threadIdx.x + blockIdx.x * blockDim.x;
float sum = 0.0f;
for (int i = 0; i < mat_size; i++) {
sum += A[row * mat_size + i] * B[col + i * mat_size];
}
C[row * mat_size + col] = sum;
}
把计算结果拷贝回 Host,释放设备上申请的内存,停止计时。
0
1
2
3
4
5
6
7
cudaMemcpy(C, cuda_C, sizeof(float) * MATRIX_SIZE * MATRIX_SIZE, cudaMemcpyDeviceToHost);
PrintMatrix(C, MATRIX_SIZE, MATRIX_SIZE);
cudaFree(cuda_A);
cudaFree(cuda_B);
cudaFree(cuda_C);
clock_t endTime = clock();
在 CPU 上进行计算,与 CUDA 设备的计算结果进行比较。
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#if CHECK
float *D = (float *)malloc(sizeof(float) * MATRIX_SIZE * MATRIX_SIZE);
for (int m = 0; m < MATRIX_SIZE; m++) {
for (int k = 0; k < MATRIX_SIZE; k++) {
float tmp = 0;
for (int n = 0; n < MATRIX_SIZE; n++) {
tmp += A[m * MATRIX_SIZE + n] * B[MATRIX_SIZE * n + k];
}
D[m * MATRIX_SIZE + k] = tmp;
}
}
float max_err = 0, avg_err = 0;
for (int i = 0; i < MATRIX_SIZE; i++) {
for (int j = 0; j < MATRIX_SIZE; j++) {
if (D[i * MATRIX_SIZE + j] != 0) {
float err = fabs((C[i * MATRIX_SIZE + j] - D[i * MATRIX_SIZE + j]) / D[i * MATRIX_SIZE + j]);
if (max_err < err) max_err = err;
avg_err += err;
}
}
}
avg_err /= MATRIX_SIZE * MATRIX_SIZE;
PrintMatrix(D, MATRIX_SIZE, MATRIX_SIZE);
printf("Max error = %g\nAverage error = %g\n", max_err, avg_err);
free(D);
#endif
最后记得释放内存。
实验结果
CUDA Thread Block size 从32增加至512,矩阵规模从512增加至8192。
可以看出矩阵比较小的时候增加 CUDA Thread Block size 会增加一点时间。
当矩阵足够大的时候增加 CUDA Thread Block size 则可以加速运算速度。
| MatSIZE\BlockSize | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|
| 512 | 0.2052s | 0.2060s | 0.2140s | 0.2172s | 0.2213s |
| 1024 | 0.2137s | 0.2135s | 0.2111s | 0.2133s | 0.2214s |
| 2048 | 0.2380s | 0.2293s | 0.2352s | 0.2367s | 0.2356s |
| 4096 | 0.4239s | 0.2871s | 0.2835s | 0.2886s | 0.3105s |
| 8192 | 1.4426s | 0.5941s | 0.4904s | 0.4789s | 0.4903s |
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.