DCS293 - High Performance Computing 2021 Fall
DCS242 - Parallel and Distributed Computing 2021 Fall
背景
数学上,一个$m \times n$的矩阵是一个由$m$行$n$列元素排列成的矩形阵列。矩阵是高等代数中常见的数学工具,也常见于统计分析等应用数学学科中。通用矩阵乘法(GEMM)通常定义为:
$C=AB$
$C_{m,k}=\sum_{n=1}^{N}A_{m,n}B_{n,k}$
通过 MPI 实现通用矩阵乘法
MPI
MPI是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。
GEMM_MPIv1
代码见 GEMM_MPIv1.cpp
首先引入头文件
0
#include <mpi.h>
使用MPI首先需要初始化:
0
1
2
3
4
5
6
7
8
int main(){
...
int comm_sz, my_rank;
MPI_Comm comm = MPI_COMM_WORLD;// MPI通信子
MPI_Init(NULL, NULL); // 初始化MPI
MPI_Comm_size(comm, &comm_sz); // 获取通信子大小(进程数量)
MPI_Comm_rank(comm, &my_rank); // 获取进程编号
MPI_Status status;
...
我们的思路是把矩阵A按行分成块,然后每个进程计算这部分A和B的乘积,假设 #n 进程计算A的a到b行和B相乘,得到的部分C也就是C的a到b行的结果。这就需要我们根据进程数量将A分块,我们让 #0 进程负责收发消息,其他进程负责计算。
0
1
2
3
4
...
// 本进程开始的行,结束的行,平均前n-2进程计算的行的数量
// 最后一个进程计算剩下的大于等于avg_rows小于2*avg_rows行
int begin_Arow, end_Arow, avg_rows;
if (comm_sz > 1) avg_rows = M / (comm_sz - 1);
然后我们让 #0 进程来循环发消息给其他所有进程
0
1
2
3
4
5
6
7
8
9
if(my_rank == 0){
for (i = 0; i < comm_sz - 1; i++) {
// 判断是不是最后一个进程,是的话把剩的全发过去
begin_Arow = avg_rows * i, end_Arow = i + 1 == comm_sz - 1 ? MAX(M, avg_rows * (i + 1)) : avg_rows * (i + 1);
// start row 可以计算得出,而最后一个进程的 end row 可能有些不一样,所以额外发送。
MPI_Send(&end_Arow, 1, MPI_INT, i + 1, 10, MPI_COMM_WORLD);
MPI_Send(&A[begin_Arow * N], (end_Arow - begin_Arow) * N, MPI_FLOAT, i + 1, 1, MPI_COMM_WORLD); // some rows of matrix A
MPI_Send(B, N * K, MPI_FLOAT, i + 1, 2, MPI_COMM_WORLD); // whole matrix B
}
...
然后 #0 进程就可以等大家都算完然后接受信息了。由于 MPI_Recv() 是阻塞函数,所以我们直接写在发送的后面就行,#0 会在收到消息前等待。
0
1
2
3
4
5
...
for (i = 0; i < comm_sz - 1; i++) {
begin_Arow = avg_rows * i, end_Arow = i + 1 == comm_sz - 1 ? MAX(M, avg_rows * (i + 1)) : avg_rows * (i + 1);
MPI_Recv(&C[begin_Arow * N], (end_Arow - begin_Arow) * K, MPI_FLOAT, i + 1, 3, MPI_COMM_WORLD, &status);
}
} // end of if(my_rank == 0)
然后如果不是 #0 进程的话,就需要先接收 #0 进程发来的消息。然后计算,然后把结果发给 #0 进程。
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
if (my_rank != 0) {
MPI_Recv(&end_Arow, 1, MPI_INT, 0, 10, MPI_COMM_WORLD, &status);
begin_Arow = avg_rows * (my_rank - 1); // end_Arow = MIN(K, avg_rows * (my_rank + 1));
printf("rank%d:\nfrom %d to %d\n", my_rank, begin_Arow, end_Arow);
localA = (float *)malloc(sizeof(float) * (end_Arow - begin_Arow) * N);
localB = (float *)malloc(sizeof(float) * N * K);
localC = (float *)malloc(sizeof(float) * (end_Arow - begin_Arow) * K);
MPI_Recv(localA, (end_Arow - begin_Arow) * N, MPI_FLOAT, 0, 1, MPI_COMM_WORLD, &status);
MPI_Recv(localB, N * K, MPI_FLOAT, 0, 2, MPI_COMM_WORLD, &status);
matrix_multiply(end_Arow - begin_Arow, N, K, localA, localB, localC); // 计算
MPI_Send(localC, (end_Arow - begin_Arow) * K, MPI_FLOAT, 0, 3, MPI_COMM_WORLD); // 发送结果
free(localA);
// free(localB);
free(localC);
}
最后使用
0
MPI_Finalize();
来终止MPI。
编译
编译本程序使用 mpicxx,编译C写的可以使用 mpicc
0
mpicxx -g -Wall -o GEMM_MPIv1 GEMM_MPIv1.cpp
运行
运行MPI程序
0
mpiexec -n <comm_sz> ./GEMM_MPIv1
其中 <comm_sz> 是进程数量。
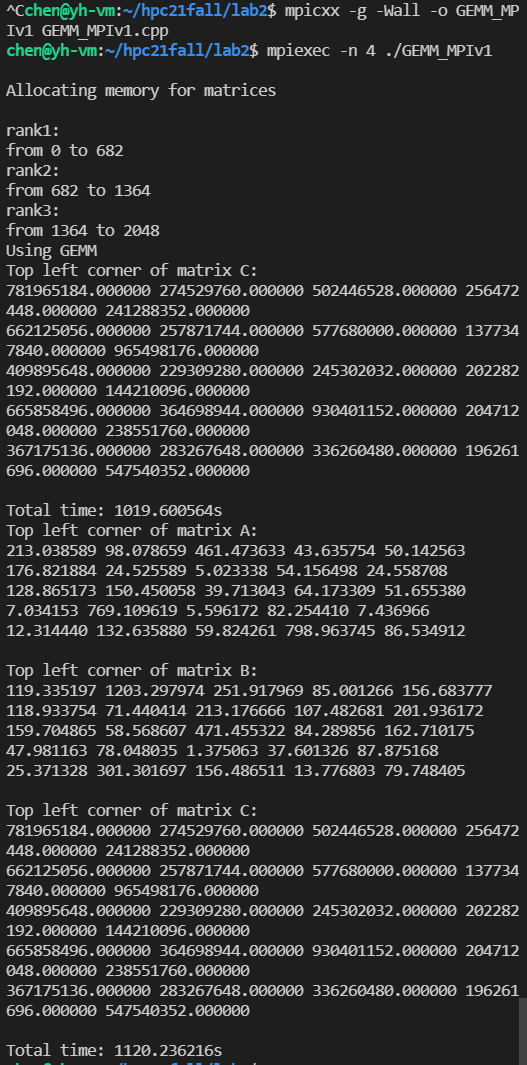
在本地虚拟机采用rank size=4矩阵边长2048跑出来的结果,和串行对比:
并行用了1120s,串行用了1019s。可以看到运算结果是正确的。
基于 MPI 的通用矩阵乘法及其优化
在实验一已经实现了点对点通信,我们使用 #0 进程来循环分别对其他进程发送A矩阵的某些行和整个B矩阵,然后其他进程运算完成再发给 #0 进程。下面我们使用 MPI_Type_create_struct 来聚合变量,优化实验一的代码。
0
1
2
3
4
5
6
int MPIAPI MPI_Type_create_struct(
int count,
_In_count_(count) int array_of_blocklengths[],
_In_count_(count) MPI_Aint array_of_displacements[],
_In_count_(count) MPI_Datatype array_of_types[],
_Out_ MPI_Datatype *newtype
);
我们发现,矩阵A需要平均分配给每个进程,而矩阵B要全部分发给每个进程,所以我们尝试采用 MPI_Scatter() 分发矩阵A,采用 MPI_Bcast() 分发矩阵B,最后使用 MPI_Gather() 来聚合每个进程的计算结果。
MPI_Scatter
0
1
2
3
4
5
6
7
8
9
int MPIAPI MPI_Scatter(
_In_ void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
_Out_ void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
MPI_Bcast
0
1
2
3
4
5
6
int MPIAPI MPI_Bcast(
_Inout_ void *buffer,
_In_ int count,
_In_ MPI_Datatype datatype,
_In_ int root,
_In_ MPI_Comm comm
);
MPI_Gather
0
1
2
3
4
5
6
7
8
9
int MPIAPI MPI_Gather(
_In_ void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
_Out_opt_ void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
注意这个count是指每一部分的数量而不是全部的数量。
这里注意一点,由于使用了 MPI_Scatter() ,所以输入矩阵大小需要为rank size的倍数。代码见 GEMM_MPIv2.cpp
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
int main(){
... // MPI_Init 等准备,申请ABC空间。
if (my_rank == 0) {
printf("avgr:%d\n", avg_rows);
printf("\nAllocating memory for matrices\n\n");
... // Allocating memory for matrices
MPI_Start = MPI_Wtime();
}
if (comm_sz == 1) { // serial
...
} else { // parallel
localA = (float *)malloc(sizeof(float) * avg_rows * N);
// localB = (float *)malloc(sizeof(float) * N * K);
localC = (float *)malloc(sizeof(float) * avg_rows * K);
printf("#%d scattering.\n", my_rank);
MPI_Scatter(A, avg_rows * N, MPI_FLOAT, localA, avg_rows * N, MPI_FLOAT, 0, MPI_COMM_WORLD);
printf("#%d Bcasting.\n", my_rank);
MPI_Bcast(B, N * K, MPI_FLOAT, 0, MPI_COMM_WORLD);
matrix_multiply(avg_rows, N, K, localA, B, localC);
printf("#%d Gathering.\n", my_rank);
MPI_Gather(localC, avg_rows * K, MPI_FLOAT, C, avg_rows * K, MPI_FLOAT, 0, MPI_COMM_WORLD);
}
if (my_rank == 0) {
MPI_End = MPI_Wtime();
#if CHECK
...
#endif
#if SHOW_MATRIX
...
#endif
printf("Total time: %lfs\n", (double)(MPI_End - MPI_Start));
free(A);
free(B);
free(C);
}
free(localA);
free(localC);
MPI_Finalize();
return 0;
}
运行
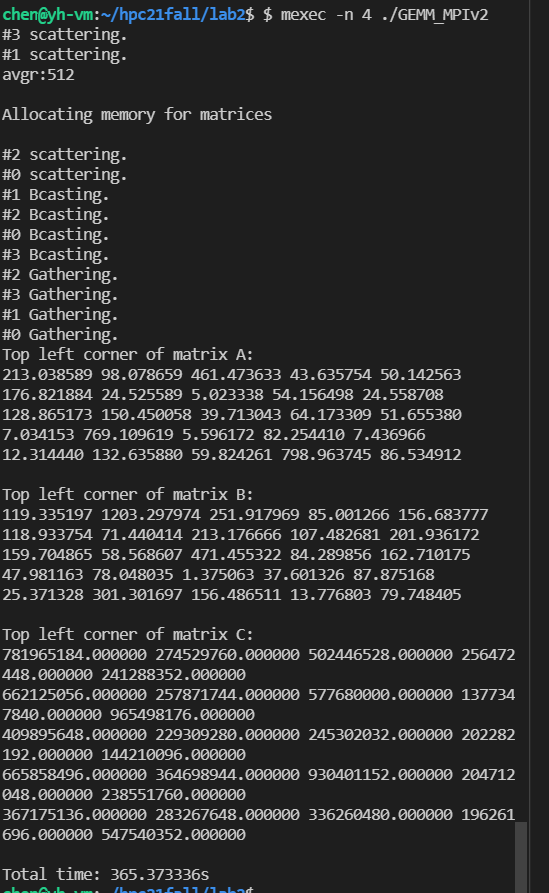
当ranksize=4,矩阵边长为2048时运算时间为365s,比上面点对点通信的1120s快了不少。
遇到问题
一开始运行实验一出现了这种问题
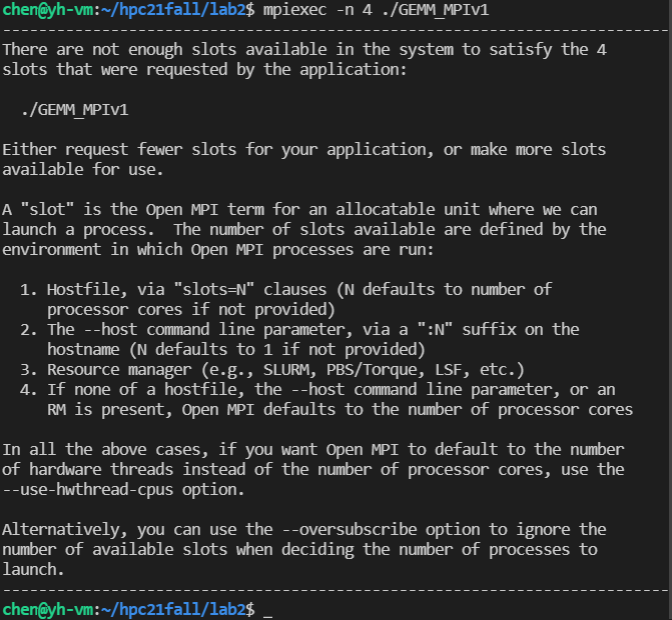
发现虚拟机只设置了两个处理器。开了4个处理器便可以用4进程运行了。
我的机器最多只能开启两个处理器一共4个核,所以不能用8进程运行,提交到超算习堂它又跑不出来,可能溢出了,只有把矩阵大小缩小才能跑出来。
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.